Evaluation of deep learning performance of Genesis Cloud GPU computing infrastructure using Arhat framework and object detection models

Editor’s Note
The article is written by Alexey Gokhberg who has developed Arhat. “We” in the article does not refer to Genesis Cloud GmbH but to Alexey and the co-developers of Arhat. Alexey Gokhberg acts as a consultant for Genesis Cloud GmbH.
Introduction
Genesis Cloud is a provider of GPU cloud computing services. Genesis Cloud aims at high cost efficiency by offering the GPU computing power at prices that are substantially lower than other major cloud providers. The cloud infrastructure is suitable for a wide range of applications from machine learning and visual effects rendering to big data analytics. To cater for these requirements, Genesis Cloud provides a rich feature set optimized for machine learning. In this study we apply our deep learning framework Arhat for performance evaluation of Genesis cloud GPU infrastructure for inference with a representative collection of popular object detection models.
About Arhat
Arhat is a cross-platform framework designed for efficient deployment of deep learning inference workflows in the cloud and on the edge. Unlike the conventional deep learning frameworks Arhat translates neural network descriptions directly into lean standalone executable code. In developing Arhat, we pursued two principal objectives:
- providing a unified platform-agnostic approach towards deep learning deployment and
- facilitating performance evaluation of various platforms on a common basis
Challenges of deep learning deployment
Arhat addresses engineering challenges of modern deep learning caused by high fragmentation of its hardware and software ecosystems. This fragmentation makes deployment of each deep learning model a substantial engineering project and often requires using cumbersome software stacks.
Currently, the deep learning ecosystems represent a heterogeneous collection of various software, hardware, and exchange formats, which include:
- training software frameworks that produce trained models,
- software frameworks designed specifically for inference,
- exchange formats for neural networks,
- computing hardware platforms from different vendors,
- platform-specific low level programming tools and libraries.
Training frameworks (like TensorFlow, PyTorch, or CNTK) are specialized in construction and training of deep learning models. These frameworks do not necessarily provide the most efficient way for inference in production, therefore there are also frameworks designed specifically for inference (like OpenVINO, TensorRT, MIGraphX, or ONNX runtime), which are frequently optimized for hardware of specific vendors. Various exchange formats (like ONNX, NNEF, TensorFlow Lite, OpenVINO IR, or UFF) are designed for porting pre-trained models between the software frameworks. Various vendors provide computing hardware (like CPU, GPU, or specialized AI accelerators) optimized for deep learning workflows. Since deep learning is very computationally intensive, this hardware typically has various accelerator capabilities. To utilize this hardware efficiently, there exist various platform-specific low level programming tools and libraries (like Intel oneAPI/oneDNN, NVIDIA CUDA/cuDNN, or AMD HIP/MIOpen).
All these components are evolving at a very rapid pace. Compatibility and interoperability of individual components is frequently limited. There is a clear need for a streamlined approach for navigating in this complex world.
Benchmarking of deep learning performance represents a separate challenge. At present, teams of highly skilled software engineers are busy with the tuning of a few popular models (ResNet50 and BERT are the favorites) to squeeze the last bits of performance from their computing platforms. However, the end users frequently want to evaluate performance of models of their own choice. Such users request methods for achieving the best inference performance on the chosen platforms as well as interpreting and comparing the benchmarking results. Furthermore, they typically have limited time and budget, and might not have in their disposition a dedicated team of deep learning experts. Apparently, this task presents some interesting challenges requiring a dedicated set of tools and technologies.
Reference architecture
To address these challenges, we have developed Arhat. The main idea behind it is quite simple: what if we can generate executable code individually for each combination of a model and a target platform? Obviously, this will yield a rather compact code and can greatly simplify the deployment process. Conceptual Arhat architecture as originally designed is shown on the following figure.
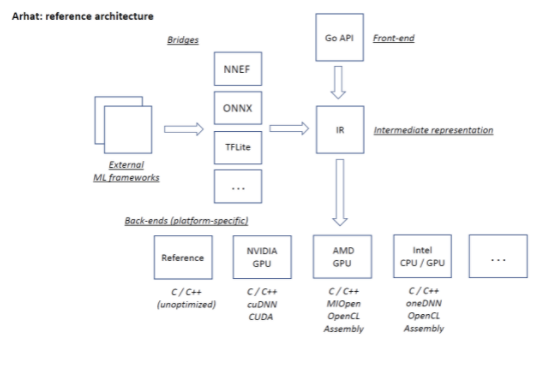
The central component is the Arhat engine that receives model descriptions from various sources and steers back-ends generating the platform-specific code. There are two principal ways for obtaining model descriptions:
- Arhat provides the front-end API for programmatic description of models.
- Pre-trained models can be imported from the external frameworks via bridge components supporting various exchange formats.
The interchangeable back-ends generate code for various target platforms.
This architecture is extensible and provides regular means for adding support for new model layer types, exchange formats, and target platforms. Arhat core is implemented in pure Go programming language. Therefore, unlike most conventional platforms that use Python, we use Go also as a language for the front-end API. This API specifies models by combining tensor operators selected from an extensible and steadily growing operator catalog. The API defines two levels of model specification. The higher level is common for all platforms and workflows. The lower level is platform- and workflow-specific. The Arhat engine performs automated conversion from the higher to the lower level.
Case study: object detection
We have validated the approach using as a case study object detection on embedded platforms. For this study we have selected 8 representative pre-trained models of 3 different families (SSD, Faster R-CNN, and YOLO) from OpenVINO Model Zoo.
These models include:
- SSD
- ssd_inception_v1_fpn_coco (640 x 640)
- ssd_inception_v2_coco (300 x 300)
- ssd_resnet50_v1_fpn_codo (640 x 640)
- Faster R-CNN
- faster_rcnn_mobilenet_v2_coco (600 x 1024)
- faster_rcnn_resnet50_coco (600 x 1024)
- YOLO
- yolo_v2_tf (608 x 608)
- yolo_v3_tf (416 x 416)
- yolo_v4_tf (608 x 608)
(The input image sizes are shown in parentheses.)
We used Arhat to generate code for NVIDIA computing platform and evaluated it on two GPU devices available on Genesis Cloud, NVIDIA RTX 3080 and RTX 3090. As a baseline, we added performance figures for a less powerful GPU installed on our development workstation, NVIDIA RTX 2080.
For these experiments, we used two different back-ends targeting inference on NVIDIA GPU devices. The first back-end generates C++ code that interacts directly with CUDA and cuDNN libraries. Code generated by the second back-end interacts with the TensorRT inference library.
Converting models with OpenVINO
Intel OpenVINO toolkit allows developers to deploy pre-trained models on various Intel hardware platforms. It includes the Model Optimizer tool that converts pre-trained models from various popular formats to the uniform Intermediate Representation (IR). We leverage OpenVINO Model Optimizer for supporting various model representation formats in Arhat. For this purpose, we have designed the OpenVINO IR bridge that can import models produced by the OpenVINO Model Optimizer. This immediately enables Arhat to handle all model formats supported by OpenVINO. The respective workflow is shown on the following figure.
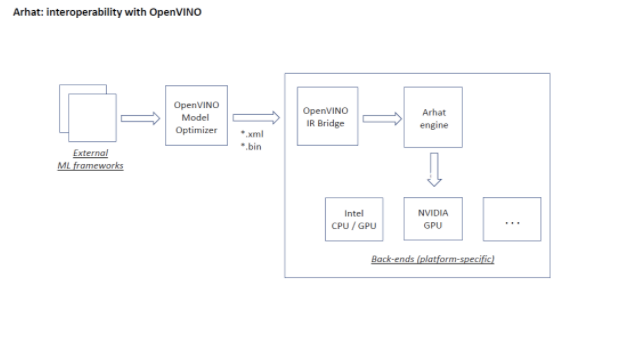
With Arhat, the end-users can view OpenVINO as a vendor-neutral solution suitable for deploying deep learning inference on a wide range of computing platforms.
Interoperability with TensorRT
To run OpenVINO models on TensorRT we have implemented a specialized Arhat back-end generating code that calls TensorRT C++ inference library instead of cuDNN.
Arhat back-end for TensorRT enables native deployment of OpenVINO models on NVIDIA GPUs. The respective workflow is shown on the following figure.
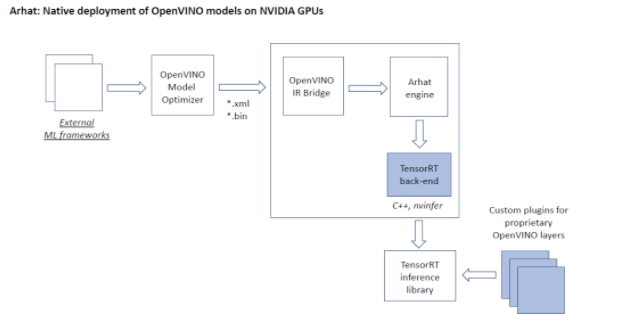
There are several OpenVINO proprietary layer types that are not directly supported by TensorRT. We have implemented them in CUDA as custom TensorRT plugins. These layer types include:
- DetectionOutput
- PriorBoxClustered
- Proposal
- RegionYolo
- RoiPooling
Performance evaluation
For each model, GPU device, and back-end we have measured average processing time for one image frame. Separate test runs have been made for the CPU cores and the GPU. As a baseline, we also included metrics for the ResNet50 image classification network.
For RTX 3080 and 3090 we used Genesis Cloud instances with the following configuration:
- CPU: Intel Xeon Skylake, 4 cores
- OS: Ubuntu 20.04.1
- CUDA: 11.3.1
- cuDNN: 8.2.1
- TensorRT: 8.0.1.6
For RTX 2080 we used a desktop PC with the following configuration:
- CPU: Intel Core i7-9700K, 8 cores
- OS: Windows 10 Pro
- CUDA: 10.2,89
- cuDNN: 8.2.0
- TensorRT: 7.2.3.4
Benchmarking results are summarized in the following table. All numbers represent time in milliseconds.
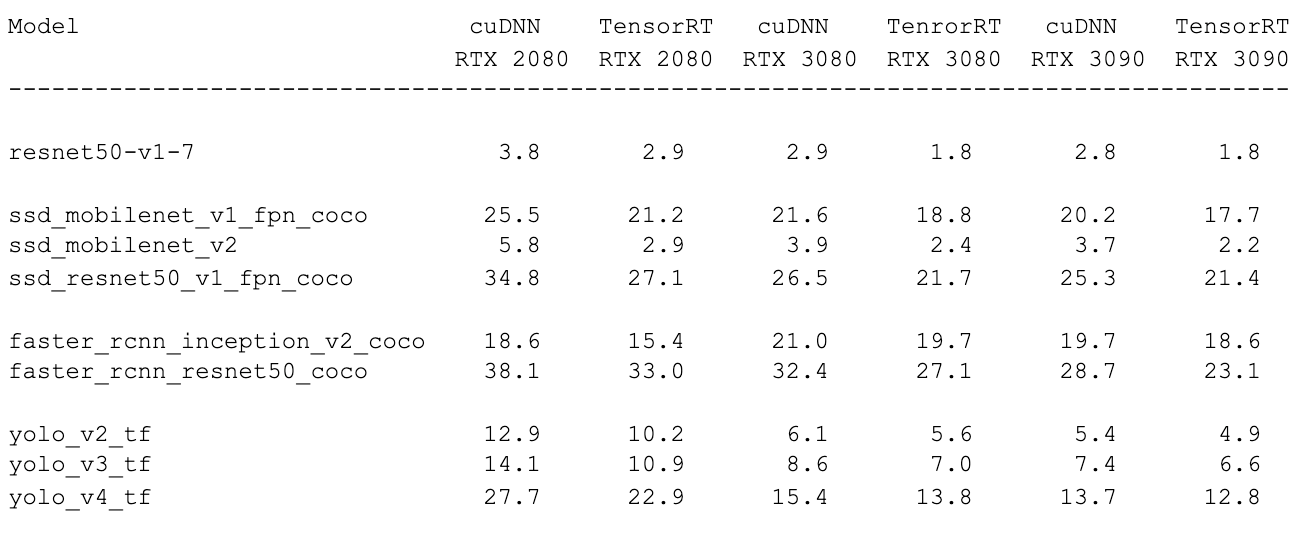
These numbers show that TensorRT inference library provides significantly better performance than cuDNN. This agrees with some other publicly available benchmarking results. It is known that TensorRT applies aggressive layer merging not available in cuDNN. NVIDIA software is not available as open source, therefore more detailed analysis is currently not possible.
It is worth noting that object detection neural networks typically use layers that are difficult to implement on the GPU. Such layers are frequently implemented on the CPU, which can significantly affect performance.
Conclusion
This study demonstrated that recently introduced GPU devices provided by Genesis Cloud (NVIDIA RTX 3080 and 3090) are highly efficient for the purpose of object detection inference and in most cases provide significant performance improvement over the GPUs of previous generations.
Furthermore, Arhat can be used for the streamlined on-demand benchmarking of models on various platforms. Using Arhat for performance evaluation eliminates overhead that might be caused by external deep learning frameworks because code generated by Arhat directly interacts with the optimized platform-specific deep learning libraries.
When used for deployment of inference workflows, Arhat can combine heterogeneous tools of different vendors (like Intel OpenVINO and NVIDIA TensorRT in this case) that are most suitable for handling the given task.
Written on September 13th, 2021 by Alexey Gokhberg