Llama 2 is out! Is it really better than ChatGPT? Here is what you need to know.

Introduction
In this blog post, we’re going to explore the process that Meta uses to build and train Llama 2 models. We’ll start with the basic foundation of transformers as outlined in the paper “Attention is All You Need,” and see how big companies use a technique called RLHF to balance the helpfulness and safety of their models.
We’ll define the key terms you need to understand how a large language model (LLM) is structured, pre-trained, evaluated, and fine-tuned to perform a specific task or even multiple tasks at once.
Next, we will review the results from the LLaMa 2 paper and compare it with the state-of-the-art models currently available, both open and closed source.
Lastly, we will cover parameter-efficient fine-tuning (PEFT) techniques like LoRa and QLoRa. These are smart fine-tuning methods that achieve good results without needing lots of compute power.
Llama 2 training process
First, let’s explore how we build Large Language Models (LLMs), with the Llama 2 Model as our main example. Both closed and open-source LLMs are inspired from the popular “Attention is All You Need” paper. This paper introduced the world to the standard transformer architecture, which marked the beginning of a new era in the creation of LLMs. If you want to dig deeper, This article introduces transformer models and guides you through their installation on a Genesis Cloud GPU instance. It also highlights key NLP tasks they can address.
Building Llama 2 is much like creating OpenAI’s GPT-3.5, as both processes involve three key steps. The first step is pre-training on a substantial dataset. For Meta, this involves the use of entirely public datasets, as about 2 trillion tokens were used to train their model. LLaMa 1 and Llama 2 differ in two main ways. First, Llama 2 can remember more information at once, which we refer to as the context length or the context window which simply means the length of the prompt. Second, a different mix of data was used to train Llama 2 which contains 40% more. Besides these differences, the training settings for both versions are largely similar.
In the next stage, a chat-oriented version of Llama 2 (Llama-2-Chat) is created using a method known as Supervised Fine-Tuning (SFT). This technique uses fewer but more impactful examples (around 27,000), instead of millions of okay ones. Meta’s team found that using high-quality examples was more efficient, leading them to their key insight: “Quality is All You Need”. It’s also important to know that this fine-tuning process was performed only over 2 epochs.
The third step involves refining the SFT model using a method known as Reinforcement Learning from Human Feedback (RLHF). This is crucial in helping the model better understand and produce responses that resemble those of a human.
To understand RLHF, we must first grasp the concept of reinforcement learning. In simple terms, consider a scenario where a player, or an ‘agent’, is learning to achieve a goal in a specific environment. The agent receives rewards for each move it makes, and over time, it learns a successful strategy, or ‘policy’. This policy allows the agent to make more effective decisions, ultimately leading to the successful accomplishment of its goal with a minimal loss. When we apply this concept to fine-tuning an LLM using human feedback, think of the LLM as the agent. The environment is the vast vocabulary of tokens it can choose from, and each action the agent takes involves generating the next token. The ultimate goal is to produce the most accurate and relevant completion based on the task at hand.
In the context of LLMs, we want our model to perform in a human-like manner. This involves checking if the model’s answers, or completions, are helpful to the person asking the questions, or the prompter. To do this, we have people score the model’s answers based on two main evaluations: helpfulness and safety. Helpfulness refers to how well Llama 2-Chat responses fulfil users’ requests and provide requested information, while safety ensures the responses are not harmful or inappropriate. Utilizing these scores, the model learns to generate better, more human-like, and safer answers. However, it’s important to note that the definition of ‘safety’ used in training these models aligns with Meta’s specific values and perspectives. This interpretation of safety may not necessarily reflect a universally accepted definition or common sense understanding of safety.
The learning process employs techniques known as Proximal Policy Optimization (PPO) and Rejection Sampling fine-tuning. PPO helps the model to update its policy by taking steps that are not too far from its current policy, ensuring a stable learning process, while Rejection Sampling fine-tuning helps select the best model output based on rewards. This continuous improvement process is a testament to the fact that even in 2023, human involvement remains a crucial element in making a model behave more like a human. Furthermore, to address limitations in dialogue control, Meta researchers introduced a novel technique called Ghost Attention (GAtt), a method that enables dialogue control over multiple turns by synthetically creating additional training data with specific instructions for the model. This helps prevent the model from forgetting the initial instruction during the conversation.
This figure below depicts the training process for Meta Llama-2 explained before:
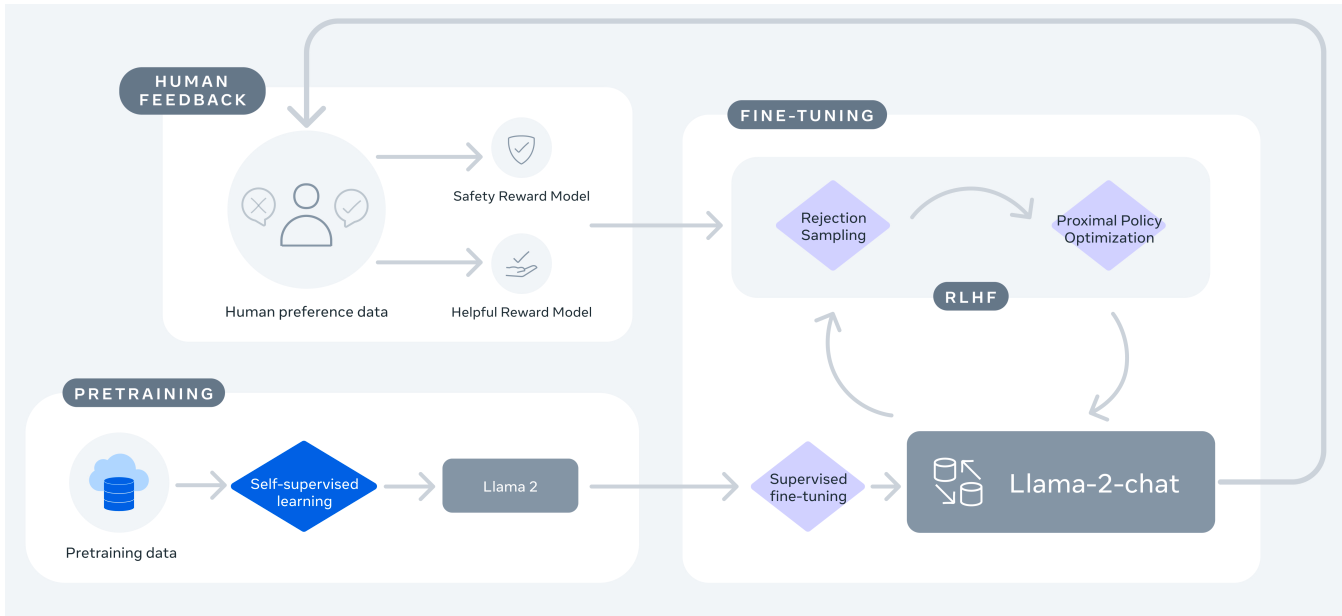
Evaluation
As Large Language Models (LLMs) continue to evolve, it’s becoming increasingly important to compare them and identify the one best suited for specific tasks. To facilitate this, recent research has introduced various benchmarks for LLMs. These benchmarks aim to provide a more comprehensive comparison from a broader perspective. The figure below, taken from the Llama 2 paper, presents a comparative analysis of the largest pre-trained Llama 2 model with 70 billion parameters, alongside the closed-source models GPT and PaLM, offered by OpenAI and Google respectively.
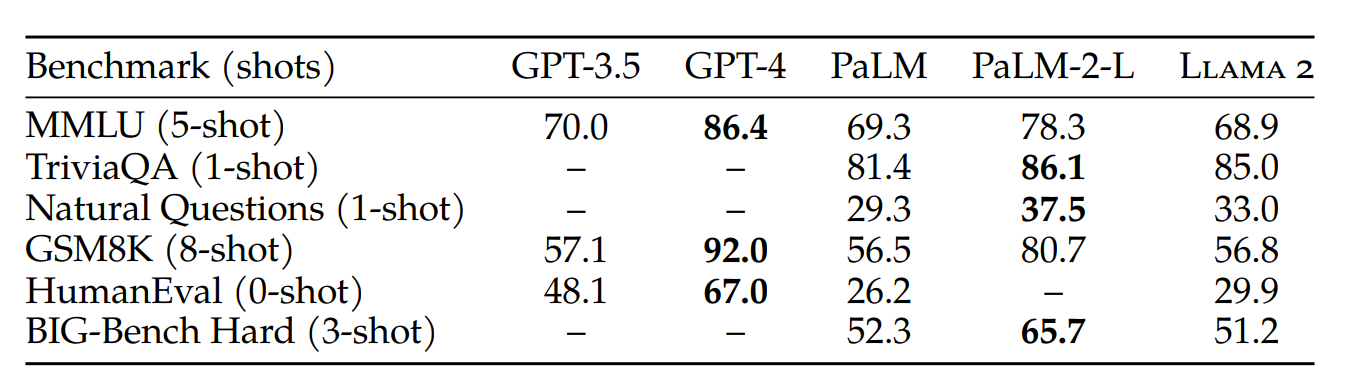
Before diving into the details of this comparison taken from the Llama 2 paper, let’s first explain the structure of the table. You might have noticed references to ‘shots’ in each benchmark, are we shooting the models? Yes, we are, but with example prompts rather than bullets. Simply put, 0-shot or Zero-shot inference refers to when we ask the model to perform a task without giving it any examples of how it should formulate its responses. Here, we rely entirely on its general understanding from the training data. 1-shot or One-shot inference is when we provide the model with an example of the desired response within the prompt. The model then attempts to generalize based on its existing knowledge and the example we provide. As you may have already deduced, n-shot or few-shot inference refers to cases when we give the model more than one example and let it learn the underlying pattern of responses. Given that the context window cannot accommodate hundreds of examples, we typically choose a number of examples less than 10. Now that you understood the shots, you need to understand the shooters, which are in our case the benchmarks. Before diving into the specific benchmarks utilized in the table above, let’s familiarize ourselves with some common metrics used to evaluate LLMs.
Perplexity is a common metric used to measure how well a model can predict a sample. The Bilingual Evaluation Understudy (BLEU) Score checks how similar a machine-generated text is to one that a human wrote; it’s mostly used in machine translation. The ROUGE (Recall-Oriented Understudy for Gisting Evaluation) Score is a typical metric for evaluating summarization tasks, where it compares the output to some reference summaries.
However, if we’re talking about the Llama 2 model; like any other large large language model, it’s a comprehensive model capable of performing multiple tasks, including but not limited to summarization and machine translation. That said, more generalized evaluation tests are required for such models, and these are the ones finally represented in the table.
Allow me to walk you through these benchmarks:
The MMLU is a test that includes 57 tasks covering a wide range of fields, including law, mathematics, computer science, history, and more. TruthfulQA is a benchmark designed to measure a model’s tendency to reproduce falsehoods commonly found online. The Natural Questions dataset, which pairs Google queries with related Wikipedia pages, trains machines to answer questions. These pages contain passages annotated to answer the query and short answer spans within the passage. Moving on, we have the GSM8K (Grade School Math 8K), a dataset composed of 8.5K high-quality, linguistically diverse grade school math word problems. The HumanEval dataset, released by OpenAI, features 164 handcrafted programming challenges, accompanied by unit tests to verify the viability of a proposed solution. Lastly, the BIG-Bench Hard (BBH) dataset consists of a subset of 23 challenging tasks from the BIG-Bench evaluation suite. Previous language models were unable to outperform average human rater performance on these tasks, which typically require multi-step reasoning and complex problem-solving capabilities.
Even though these benchmark tests cover a wide range of tasks, they don’t include everything. Your specific, custom fine-tuning task might not be covered by these benchmark tests. In such cases, you’ll need to test your model’s output on your own. Don’t hesitate to invite your friends over for a ‘review-my-model’ dinner!
Going back to the table (if you’ve forgotten about it please take another look 😉), we can now easily understand the comparative results. These show that while Llama 2 is competitive with earlier versions of GPT and PaLM, it cannot yet compete with GPT-4 and PaLM-2-L on most benchmark tests. This provides a clear answer to our initial question: ‘Is Llama 2 really better than ChatGPT?’ Unfortunately, as it stands, the answer is no.
Parameter-Efficient Fine-Tuning
Despite its limitations in competing with closed-source foundation models, Llama 2 offers intriguing opportunities for businesses thanks to its free commercial use license. It allows businesses to fine-tune the model to suit their unique needs. However, fine-tuning this model can be computationally demanding, often requiring a significant number of GPUs. This is where Parameter-Efficient Fine-Tuning (PEFT) comes into play.
PEFT mitigates the resource intensity associated with full fine-tuning, which traditionally updates all model weights. Instead, PEFT focuses on updating a limited subset of LLM parameters. By freezing most of the original weights, it significantly reduces the memory footprint, typically involving just 15-25% of the original LLM weights. This approach not only enables fine-tuning on a single GPU, but also mitigate the storage burden associated with multiple large models for different tasks.
LoRA
One of the PEFT techniques that has demonstrated effectiveness in boosting task performance is Low-rank Adaptation, or LoRA. Unlike full fine-tuning which updates all model weights as mentioned earlier, LoRA introduces a pair of smaller low-rank decomposition matrices alongside the frozen weights as shown in the figure below:
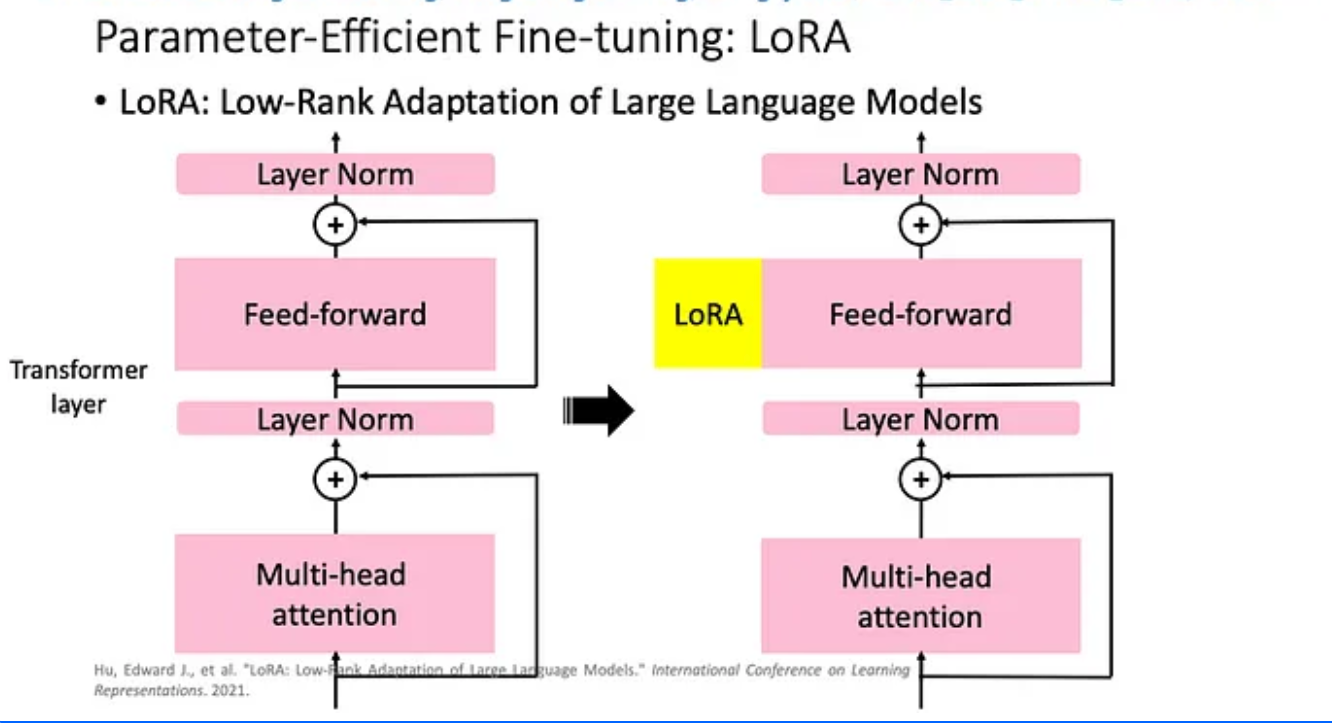
To put it simply, LoRa adds minimal trainable parameters, called adapters, for each LLM layer and freezes the original parameters. In this case, fine-tuning only requires updating the adapter weights, significantly reducing memory usage.
During inference, these matrices multiply together, forming a matrix of the same dimensions as the original weights. This product replaces the frozen weights in the model, resulting in a LoRA fine-tuned model that performs the specific task with fewer trainable parameters.
Several studies and empirical results attest to the efficiency of LoRA. Businesses, especially those with resource constraints, will find value in this technique, allowing them to efficiently fine-tune Llama 2 on a single GPU, without the need for expensive distributed GPU clusters. Furthermore, the small size of the low-rank decomposition matrices permits fine-tuning for various tasks, with the flexibility to easily switch them out at inference time, and it also prevents the catastrophic forgetting — loss of prior knowledge due to fine-tuning on new tasks and therefore updating all the model’s weights — because all of the model weights are kept during fine-tuning.
Despite its advantages, it’s important to note that LoRA might not be ideal for every scenario. The task-specific nature of the technique means that each new task may require a new set of low-rank decomposition matrices. Nevertheless, for many use-cases, the benefits outweigh the drawbacks.
QLoRA
The innovation of PEFT techniques doesn’t stop there. QLoRa (Quantized LoRa), an enhanced version of LoRa, builds upon the existing technique with three critical improvements. Firstly, it introduces 4-bit NormalFloat quantization, which ensures an equal number of values in each quantization bin, preventing computational issues and errors with outlier values. Secondly, QLoRa employs double quantization, quantizing the quantization constants themselves, leading to additional memory savings. Lastly, it leverages NVIDIA unified memory for paging, simplifying memory management between CPU and GPU and ensuring seamless error-free processing. These advancements significantly reduce memory requirements during fine-tuning while maintaining nearly on-par performance with standard approaches. QLoRa’s innovative features make it an ideal choice for resource-constrained scenarios, enabling efficient fine-tuning of language models for various tasks.
Coming up in the next blog: Fine-tune your Llama 2 model on custom tasks using the magical powers of LoRa and QLoRa on a Genesis Cloud instance with just ONE GPU 😉! Plus, a quick guide to deploy your Llama 2 model and try out the crazy prompts yourself. Don’t miss our NLP wizardry journey in the next blog post. Stay tuned!
Keep accelerating 🚀
The Genesis Cloud team
Never miss out again on Genesis Cloud news and our special deals: follow us on Twitter, LinkedIn, or Reddit.
Sign up for an account with Genesis Cloud here and benefit from $15 in free credits. If you want to find out more, please write to [email protected].
Written on August 9th, 2023 by Marouane Khoukh