Multi GPU Training
Tl.dr.:
To run a model where every GPU evaluates the gradients for a part of the batch with the gradients being pooled later on, this is the required syntax.
Keras/Tensorflow:
strategy = tf.distribute.MirroredStrategy()
with strategy.scope():
model = ...
model.compile(optimizer=...,loss=..model_parallalism.)
PyTorch
model = ...
model = torch.nn.DataParallel(model)
device = torch.device('cuda')
model.to(device)
as of 6/2020
Bouquet of minor caveats
As Moor’s Law is working its way into retirement one can not just rely on computations to become faster as the underlying hardware improves. There are still plenty of ways to cram more FLOP into the second but most of them rely on running more of them in parallel as opposed to in sequence, but quicker. Finding the potential for parallelization inherently requires some knowledge about the calculation at hand. In general it is not trivial to figure out which processes do and don’t require the output of what other processes to be present.
Basic optimization can start at an operation level. Some mathematical operations, like matrix multiplication, are inherently parallelizable.
By using a machine learning framework as opposed to import math these operations can be performed by specific system implementation optimized for a CPU or even better a GPU.
A sample application could be the training of a neural network.
All the parameters are initialized, moved to the accelerator hardware (i.e. a GPU), trained and returned to the CPU.
This is all fun and games until the memory on the accelerator hardware is outgrown by the memory requirements of the model or inference time on one GPU becomes too long even with parallelized operations.
Thanks to cloud providers like Genesis Cloud acquiring additional compute resources (i.e. more GPUs) is just one slider away.

Solving all your problems using the Genesis Cloud Compute service
Nevertheless, all your models and data points now have to be present at the correct location at the right time. A problem that many smart people are working really hard to deal with. This is just to say that syntax suggested in this post is hopefully going to age badly and quickly as easier ways of distributing training load across GPUs become available.
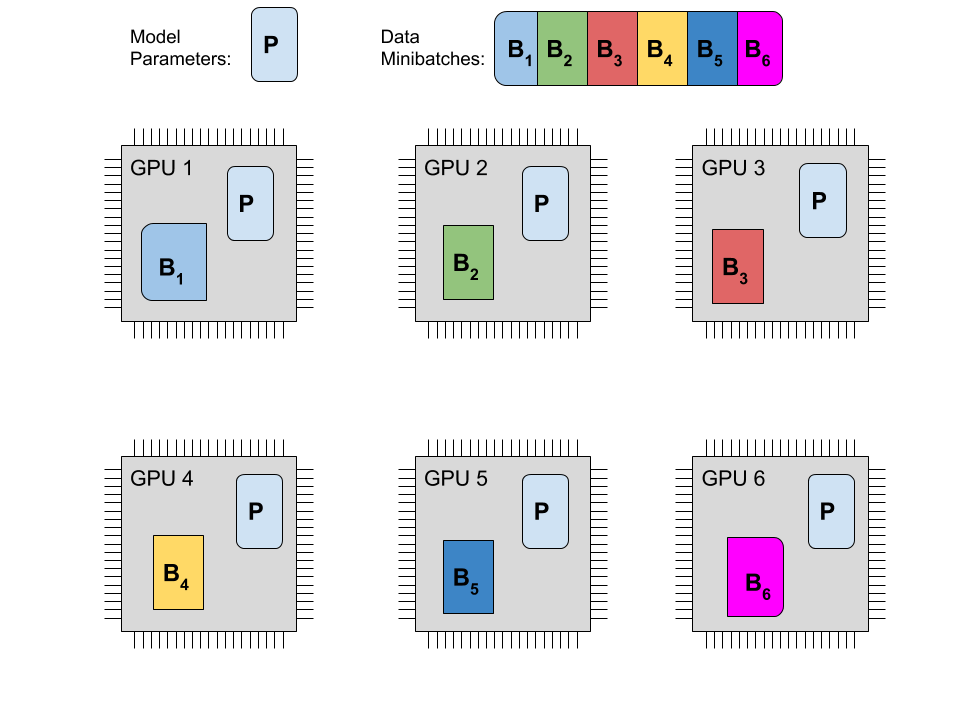
Here is a naive approach spreading computation across GPUs. To compute the gradients that will change your parameters after one training step, a prediction needs to be inferred on a number of samples. The prediction based on each sample is obviously fully independent of every other sample. This allows the data batch to be divided into however many computational units take part in training. Each unit holds a separate but identical copy of the model. After all parties have collected the changes they want to apply to the parameters these changes are pooled so that parameters are synchronized again. This is what is usually called data parallelism and it is probably the way to go for as long as a the model, its activations and all the gradients fit into GPU memory.
If that is not possible different stages of inference for one model have to be spread across multiple GPUs. This could mean that each computational unit handles a few stages of the computation. At this point the prediction based on the last few layers has to wait for at least one output of the first few layers. It’s called model parallelism and it can become really complicated.
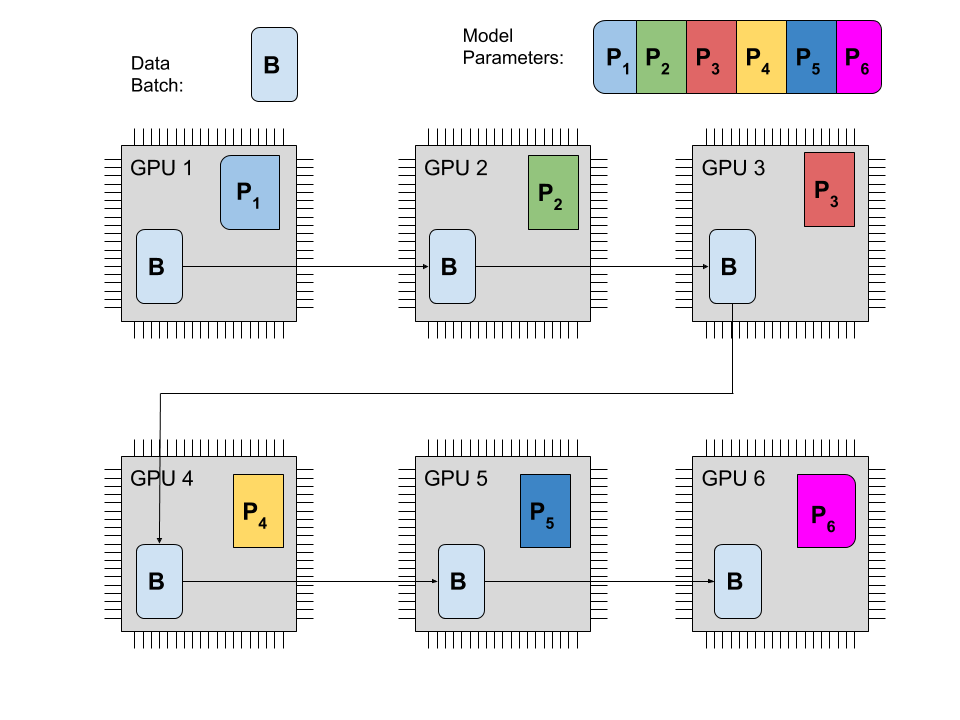
The GPU to GPU communication now creates a severe bottleneck. Tim Dettmers illustrates this in his blog post. At 32bit precision the gradient of a 1000 by 1000 weight matrix takes up 4*10⁶ bytes. A really fast 40 Gbit/s PCIe connection would take 0.75 ms to transfer the gradients as opposed to the 0.02ms that a GPU takes for a matrix multiply. This underscores that to be useful, model parallelism must minimize the data transfer between GPU nodes. If not properly scheduled one GPU might have to wait for the computation on a different core to finish, effectively reducing the overall GPU utilization. Here someone shows how to do it in PyTorch but the solution is highly specific to his model and he only achieves around half the theoretical speedup because of said communication bottlenecks.
Managing GPU Memory usage
Using the limited memory that is available to each GPU in a smart way is paramount to running a fast training job.
This can be influenced for example in the choice of batch size.
Too small of a batch size and the training is constrained by a bottleneck in the CPU-GPU interface.
Too large of a batch size and the batch does not fit on the GPU memory any more.
Yet especially for models that have to perform caching of certain outputs (like recurrent of convolutional nets) estimating the exact amount of memory that is used during training can be complicated.
One could approach this problem experimentally, set a low batch size and then check using nvidia-smi that the processes don’t go over board as the batch size is incrementally increased (Tensorflow caveats).
Yet for example for NLP applications what usually ends up clogging up the GPU memory is not big batches of input data but the model parameters themself. So for a well oiled training job Ideally the GPU DRAM is filled to the brim with no space left over during training. This is the ideal scenario:
num_gpus*memory_gpu - memory_model - b*memory_pass - memory_overhead = 0
- Pass memory is the bits that need to be stored for inference/backprop (one pass) of a single sample.
- The model memory is the space that the parameters of the model take up.
- The memory overhead is space that the is used up to manage everything. For pytorch this is somewhere close to 300 MB.
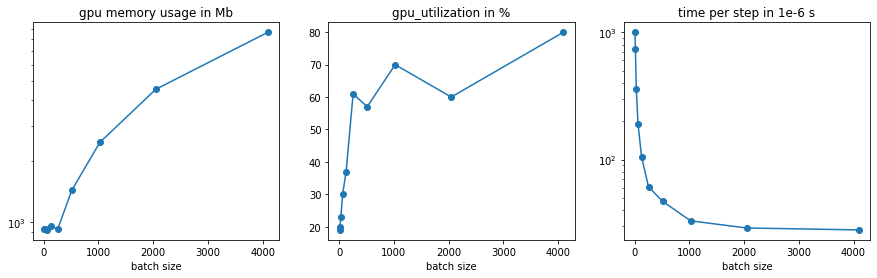
Notably only part of the memory usage actually scales linearly with the batch size. Here is a complete guide to how much memory a model will use. This plot shows how sensitive GPU performance is to changes in the batch size. It is clearly visible that as batch size is increased, GPU utilization and time per second epoch improve until a certain saturation point. Setting an even higher batch size will fail. In the example a 3 Layer CNN was trained on 3 GPUs classifying the CIFAR 100 Dataset.
The complete memory usage obviously scales with the precision of the numbers used. One can almost double size of the batch and the model when constraining 64 bit numbers to 32 bit numbers. To even further reduce the memory usage of your network, you could start offloading early parts of the activation to the CPU and get them back only when you need them. Here is somebody doing that.
Implementations
PyTorch
PyTorch makes it exceedingly easy to transfer tensors between devices.
a = torch.randn(5)
a.to(torch.device('cuda:0'))
Here the GPUs connected to the instance are named 'cuda:0','cuda:1', etc..
Computation or derivation are automatically performed at whatever location the tensors are located provided they were send there beforehand.
As this tutorial shows, this method is quite powerful but at the same time nothing that really should be done by hand every time.
As long as data parallelism is able to handle the job, that is a complete copy of the model fits onto a single GPU, there is a easier way around this.
Having constructed a model using all the standard API you can wrap it in torch.nn.DataParallel and send it to a general cuda device.
model = ...
model = torch.nn.DataParallel(model)
device = torch.device('cuda')
model.to(device)
For a full working implementation you can check out this gist.
Even for single node training jobs, speedups can be achieved by using torch.nn.DistributedDataParallel instead.
TensorFlow / Keras
TensorFlow also allows to send tensors to a specific device.
with tf.device('/device:GPU:0'):
a = tf.random.normal([5])
The devices are now named '/device:GPU:0','/device:GPU:1', …
Again, this is very powerful, but also very tedious.
In the future different distribution strategies are supposed to be included and can be chosen depending on the users needs.
For now only the MirroredStrategy is not in experimental implementation representing data parallelism.
strategy = tf.distribute.MirroredStrategy()
with strategy.scope():
model = ...
model.compile(optimizer=...,loss=...)
For a full working implementation you can check out this gist. TensorFlow is actively working towards implementations of model parallelism, check for example this repo.
Conclusion
Distributing your training load across multiple GPUs in an efficient manner is no trivial task, but we are getting there.
Written on July 15th, 2020 by Benedikt Heyl