Using Genesis Cloud GPUs with MLOps Tools: A Cost-Effective Approach to YOLOv8 Training with Clear ML

Introduction
We recently announced a collaboration between Genesis Cloud and ClearML, aimed at democratizing high-performance, sustainable computing for MLOps teams. This partnership is providing access to our instances at the most competitive rates in the market, enabling cost-effective model training for our users. Together, we aim to level the playing field and provide access to the state-of-the-art technology.
In this blog post, we will guide you through the process of training your models on Genesis Cloud instances using ClearML, the only frictionless, unified, end-to-end MLOps platform. We will also leverage ClearML’s features to present a benchmark comparison of the training costs for the cutting-edge computer vision model YOLOv8, recently released by Ultralytics, on Genesis Cloud instances versus competitors like GCP and AWS.
Spoiler Alert: We might be coy about revealing the results, but let’s be honest—you already know which instances come out on top as the most cost-effective. Our little secret against the competitors! 😉
How to use Genesis Cloud instances with ClearML
If you want to improve your MLOps game while training on GPU instances that are 100% green at the source, ClearML is the right choice. ClearML is an open-source platform that automates and simplifies the development and management of machine learning solutions for data science teams worldwide. It is designed as an end-to-end MLOps suite that allows you to focus on developing your ML code and automation. ClearML ensures that your work is reproducible and scalable.
Here are the easy steps for you to get started after setting up your ClearML account:
Step 1: Set up an auto-scaler
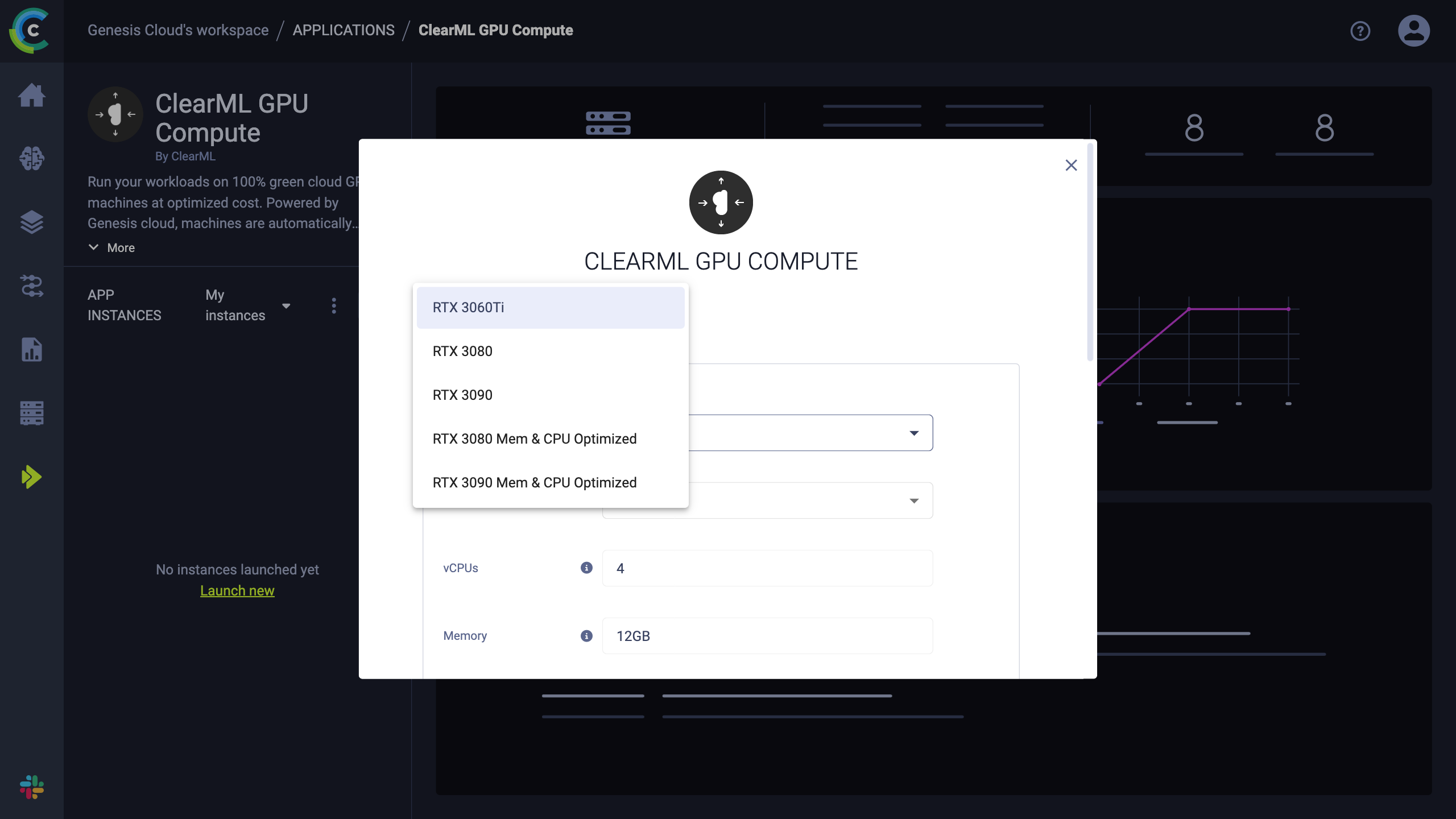
ClearML boasts an impressive feature called “auto-scaler”, which allows you to effortlessly launch remote machines to run your code and automatically shuts them down once the task is complete. To utilize this feature, open the ClearML wizard and navigate to ‘Applications.’ Click on the “+” sign and then you can choose the desired Genesis Cloud GPU instance for training your model from the exhaustive list of options available, ranging from the NVIDIA® GeForce™ RTX 3060 Ti to the Memory & CPU Optimized 3090. Once you’ve made your selection, simply click ‘Launch’ to initiate the auto-scaler. Keep in mind that the machines will not start until you begin the model training process.
Step 2: Integrate ClearML into your training code
Here comes the most important and easiest part:
After installing ClearML python package using:
pip install clearml
integrating ClearML into your training code requires only adding these two lines:
from clearml import Task
task = Task.init(project_name="YOLOv8",
task_name="detection_training")
By adding these two lines of code, your run can be captured in the ClearML Experiment Manager. Congratulations, you are now ready for the next step!
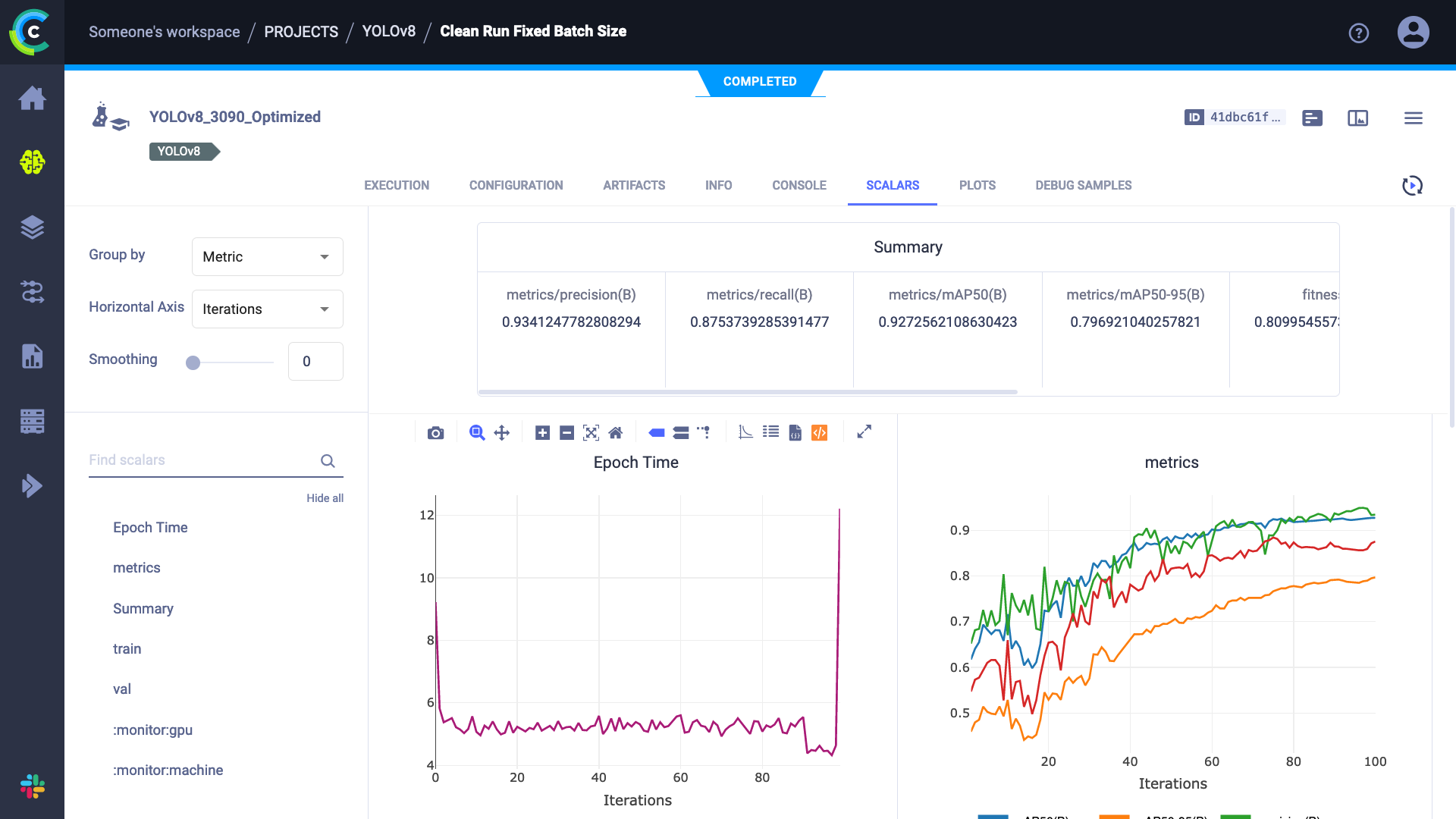
In our case, we will be training the YOLOv8 algorithm for benchmarking purposes. We will provide the complete code at the end of the steps. When utilizing ClearML for training your machine learning models, you can access an extensive range of features that provide you with valuable insights throughout the entire training process. This powerful platform enables you to monitor all the scalars, plots, and other essential metrics during and after training your model, giving you complete control and understanding of your model’s performance as you can see in the pictures below extracted from training YOLOv8:
Step 3: Customize and enqueue your experiment
In the ClearML Experiment Manager, locate your experiment, clone it, and edit the parameters to your liking. ClearML will give you the chance to edit all the hyperparameters you want. After making your desired changes, simply click ‘Save’.
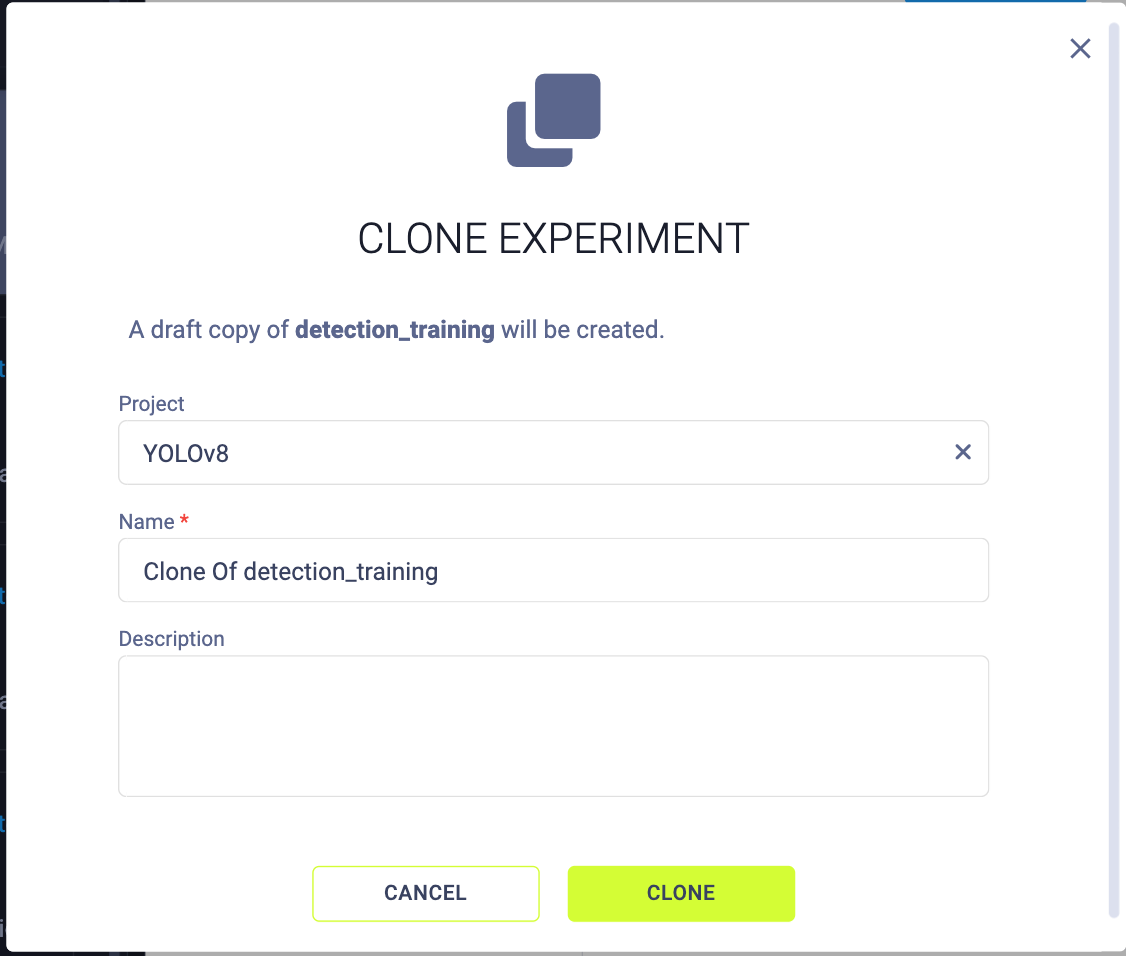
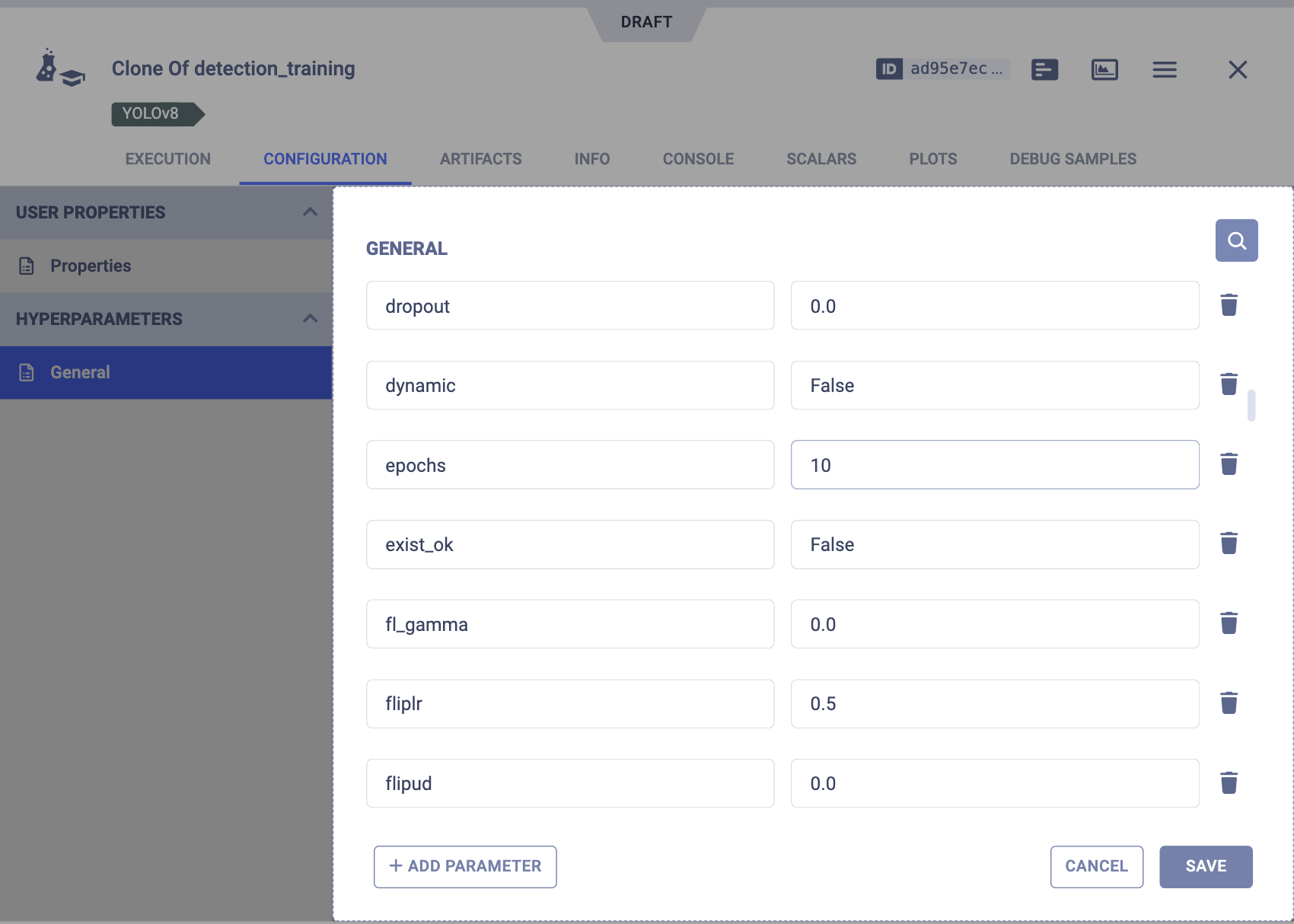
After saving the draft, if you want to run the training again with your edits, simply proceed to enqueue it as demonstrated in the following step.
Step 4: Enqueue the task
ClearML orchestrates remote machines and schedules tasks on them. After running an experiment, it stores a copy on the server. Using task queues and autoscalers, ClearML automatically allocates workers when needed. To rerun an experiment on a cloud machine, enqueue your task after you clone it and wait for the Autoscaler to detect it.
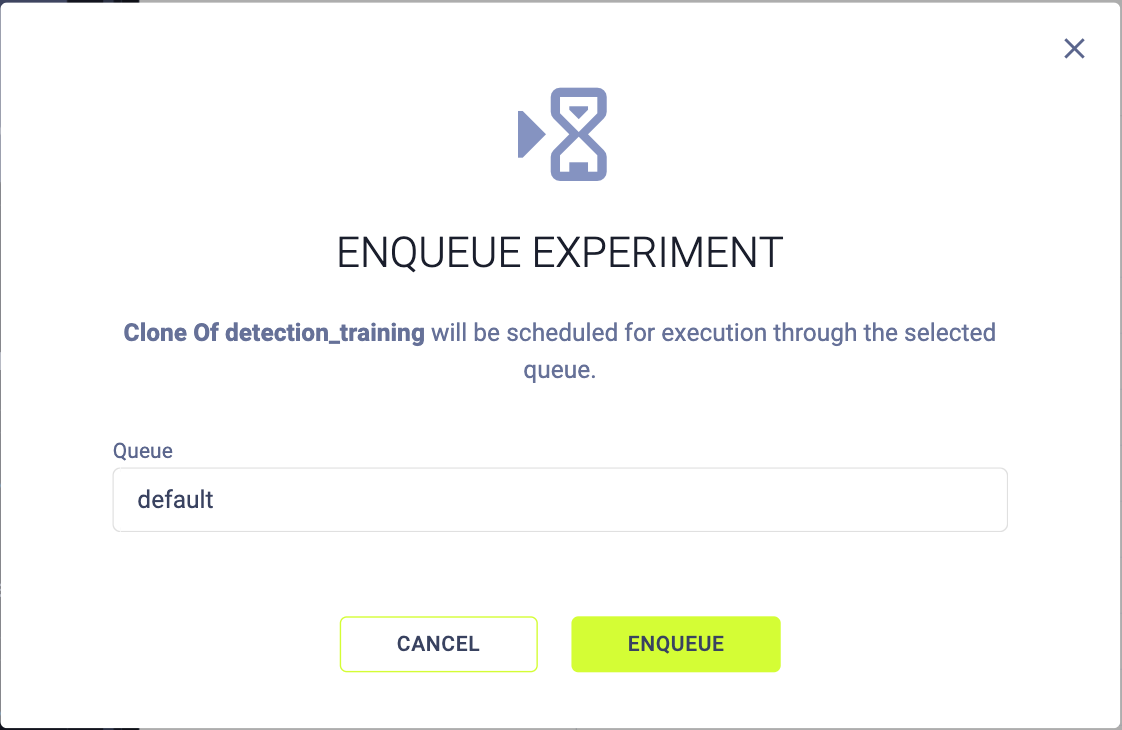
The Autoscaler will then set up a remote GPU machine to execute the task. Once the task starts running, you can monitor its progress in real time through the Experiment Manager. After it’s completed, you’ll find all relevant outputs and your newly trained model file.
This brief introduction has provided an overview of integrating ClearML into your codebase. To delve further into the incredible features it offers, consider visiting the ClearML Knowledge Base or their YouTube Channel. We guarantee that you won’t be disappointed as you uncover the full potential of this powerful platform!
ClearML recently published a blog post detailing how to use their platform to compare training results across various cloud providers, including Genesis Cloud. The post outlines a series of steps for achieving this, from integrating ClearML into your code until using their Autoscalers to remotely execute YOLOv8. In the following chapter, we will analyze the benchmarking tests conducted by ClearML, offering insights into how Genesis Cloud instances perform against their competitors
Unveiling Benchmarking Results: YOLOv8
Our friends at ClearML have penned an insightful blog post detailing the training process of the YOLOv8 object detection model on the VisDrone dataset. By leveraging ClearML’s remarkable features, they effectively compare the speed and cost-efficiency of GPU instances on Genesis Cloud with those of its cloud-based competitors. We will use the code and the results to give you a sneak peak on how to optimize the cost-effectiveness of your model and how to choose the best instance in terms of price and performance. By following the earlier instructions and incorporating minor code enhancements, you will arrive at a functional code snippet that works seamlessly, provided all necessary dependencies are installed.
Here is the whole code to train the YOLOv8:
from clearml import Task
from ultralytics import YOLO
# Explicitly call ClearML init before YOLOv8
task = Task.init(project_name="YOLOv8",
task_name="detection_training",
tags=['YOLOv8'],
)
# Set some basic settings to prepare for remote execution later
task.set_base_docker("nvidia/cuda:11.4.3-runtime-ubuntu20.04", "--ipc=host")
# Put all our YOLOv8 arguments in a dictionary and pass it to ClearML
# When later we change any parameter in the UI, it will be overridden here!
args = dict(data="VisDrone.yaml", epochs=10, imgsz=640, task='detect')
task.connect(args)
# Turn the chosen model into a parameter too, so we can change this later!
model_variant = "yolov8n"
task.set_parameter("model_variant", model_variant)
# Load the YOLOv8 model
model = YOLO(f"{model_variant}.pt") # load a pretrained model
# Train the model using our arguments from before
# If running remotely they may have been changed by ClearML
results = model.train(**args)
In the ClearML blog post, a comprehensive analysis of benchmarking results is presented, showcasing the performance of training the YOLOv8 model on Genesis Cloud instances in comparison to its competitors. Our primary focus in this discussion will be to provide you with insights into the cost-performance aspect, enabling you to make informed decisions on selecting the most cost-effective GPU instance for training your model.
We will begin by examining the following graph, which highlights the hourly cost for each machine type along with the cost per epoch, serving as a crucial measure of cost efficiency. The disparity between the hourly cost and the cost per epoch for some instances can be primarily attributed to the CPU bottleneck they face during the training process.
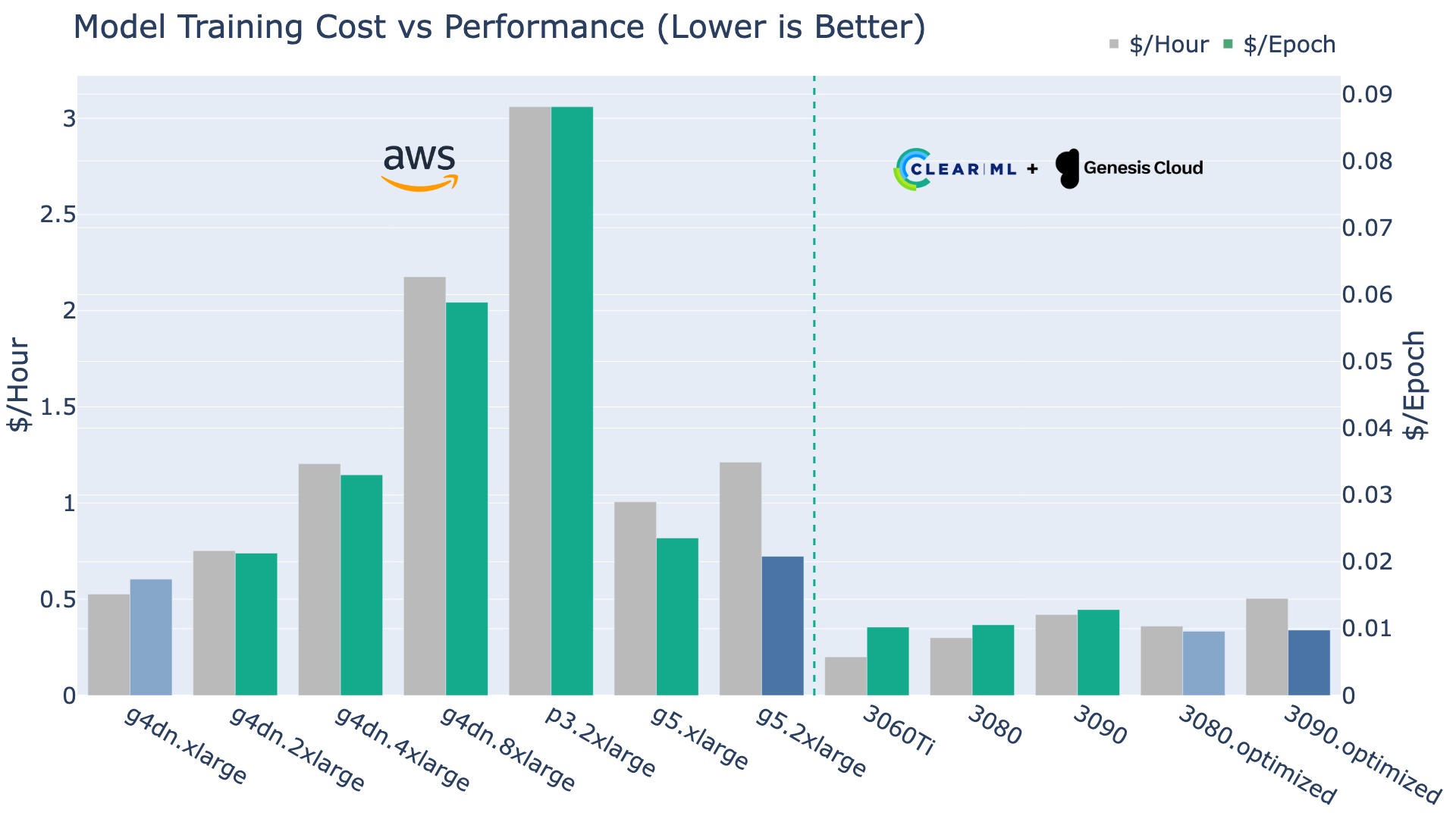
Hold onto your hats, folks! The plot thickens as we dive into the thrilling world of cost efficiency among various machine types. It becomes apparent that AWS instances may not be the most optimal choice for training a YOLOv8 model, as they tend to have a higher cost per epoch compared to their Genesis Cloud counterparts.
On the other hand, Genesis Cloud options offer a more attractive solution. The 3060Ti, while being the most affordable, has a cost of 0.0102 dollars per epoch, which is quite competitive compared to other options. However, the standard 3080 and 3090 machines, face some CPU bottleneck effects that reduce their efficiency.
The standout choices in this scenario are the Mem & CPU Optimized variants of the Genesis Cloud instances. Both the optimized 3080 and optimized 3090 machines exhibit remarkable cost efficiency, with costs of 0.0096 and 0.0098 dollars per epoch respectively. These optimized instances outshine other alternatives, making them the most cost-effective solutions for training a YOLOv8 model. To better illustrate this point, the following table provides a comprehensive comparison between Genesis Cloud and AWS instances, demonstrating the competitive edge that Genesis Cloud holds in terms of cost per epoch:
| Machine Type | Dollars / Epoch (Cost Efficiency) |
|---|---|
| ClearML + GC RTX 3080 (Mem & CPU Optimized) | 0.0096 |
| ClearML + GC RTX 3090 (Mem & CPU Optimized) | 0.0098 |
| ClearML + GC RTX 3060Ti | 0.0102 |
| ClearML + GC RTX 3080 | 0.0106 |
| ClearML + GC RTX 3090 | 0.0128 |
| AWS g4dn.xlarge | 0.0174 |
| AWS g4dn.2xlarge | 0.0213 |
| AWS g5.2xlarge | 0.0208 |
| AWS g5.xlarge | 0.0235 |
| AWS g4dn.4xlarge | 0.0330 |
| AWS g4dn.8xlarge | 0.0588 |
| AWS p3.2xlarge | 0.0881 |
As demonstrated in the table, Genesis Cloud instances outshine their AWS counterparts not only in terms of competitive pricing but also cost-effectiveness. Plus, these instances have an added bonus of being more sustainable, which isn’t necessarily the case with AWS. This combination of factors makes Genesis Cloud instances an appealing choice for training YOLOv8 models with an eye toward a greener future.
It wouldn’t be surprising if you’re already thinking about anticipating your first model training adventure on Genesis Cloud instances. 😎
Just a heads-up, if your use case allows you to train directly on Genesis Cloud instances, you might find even more budget-friendly options. Be sure to check out the recent blog post by Genesis Cloud discussing their price reduction for further insights.
Keep accelerating 🚀
The Genesis Cloud team
Never miss out again on Genesis Cloud news and our special deals: follow us on Twitter, LinkedIn, or Reddit.
Sign up for an account with Genesis Cloud here and benefit from $15 in free credits. If you want to find out more, please write to [email protected].
Written on April 6th, 2023 by Marouane Khoukh